Содержание

Требования к итоговым файлам и пост-обработка
Итак, ты уже произнес все реплики? Отлично! Теперь у тебя в Аудасити (или любом другом редакторе) есть дорожка со всеми твоими фразами. Но прежде чем кидать её на сведение, попробуй немного улучшить её, сделай немного улучшений:
- Почисти от шума. Любой, даже очень дорогой микрофон, немного шумит.
- Сделай компрессию, если звук тихий. Проверь итоговую слышимость и сохранность фраз.
- Если персонаж говорит по телефону или в каком-то тоннеле, то наложи простенькие эффекты.
- Нареж файл на мелкие части, где каждая фраза — 1 файл. Или расставь между фразами пустоту в 3 секунды.
- Сохрани результат в файл(ы) wav / flac, никаких wma! Семплрейт 44100 или 48000, 16-24-32 бита, без лучше float.
Чистка от шума
На эту тему было написано не мало мануалов. Даже тут рядом есть отличная статья.
Напишите на ютубе "ваша_программа noise reduction" и найдете тысячи видеомануалов.
Только следите за тем, чтобы шумодав не сожрал части слов, особенно шипящие звуки.
В Audacity есть замечательный режим тестирования Noise Isolation, который показывает вырезаемый шум, на фоне которого не должно быть слышно речи. Если речь есть, то попробуйте пересоздать профиль шума или изменить настройки чистки, так как в случае основного прохода все эти частички речи тоже будут обрезаны. Некорректные настройки шумодава могут вызвать неприятные "бульканья", которые еще хуже шума.
Сюда же можно отнести проблемы у некоторых актеров с шипящими буквами, например "ш" и "с", которые сильно выделяются на фоне общей речи, для этого используют фильтры-дээссеры (deesser), однако в комплекте Audacity таких нет, нужно искать отдельно.
В конце чистки можно аккуратно подрезать все что ниже 100 герц и пройтись гейтом.
Компрессия
Компрессию нужно делать всегда, по крайней мере подровнять звук нам точно не помешает, так как эмоциональные выпады непроизвольно ведут к перепадам громкости
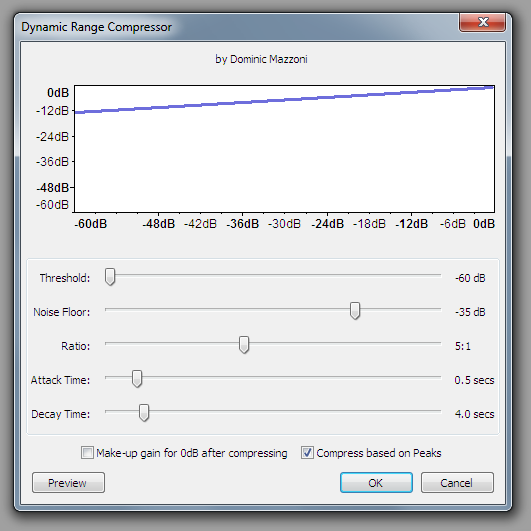
Обрати внимание, что если мы далее будем накладывать какие-то эффекты, то упираться в 0db для нас может быть опасно, ведь эффекты уже не будут иметь запаса для увеличения громкости, поэтому лучше оставить немного пустого места про запас, а уже готовый звук компрессовать еще раз.
Подробнее про компрессию тоже написано в соседней статье.
Эффекты
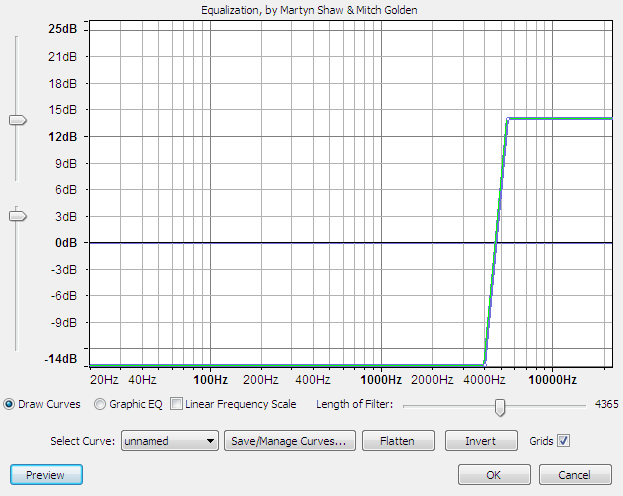
Часто персонажи говорят по телефону, этот эффект можно сделать при помощи эквалайзера:
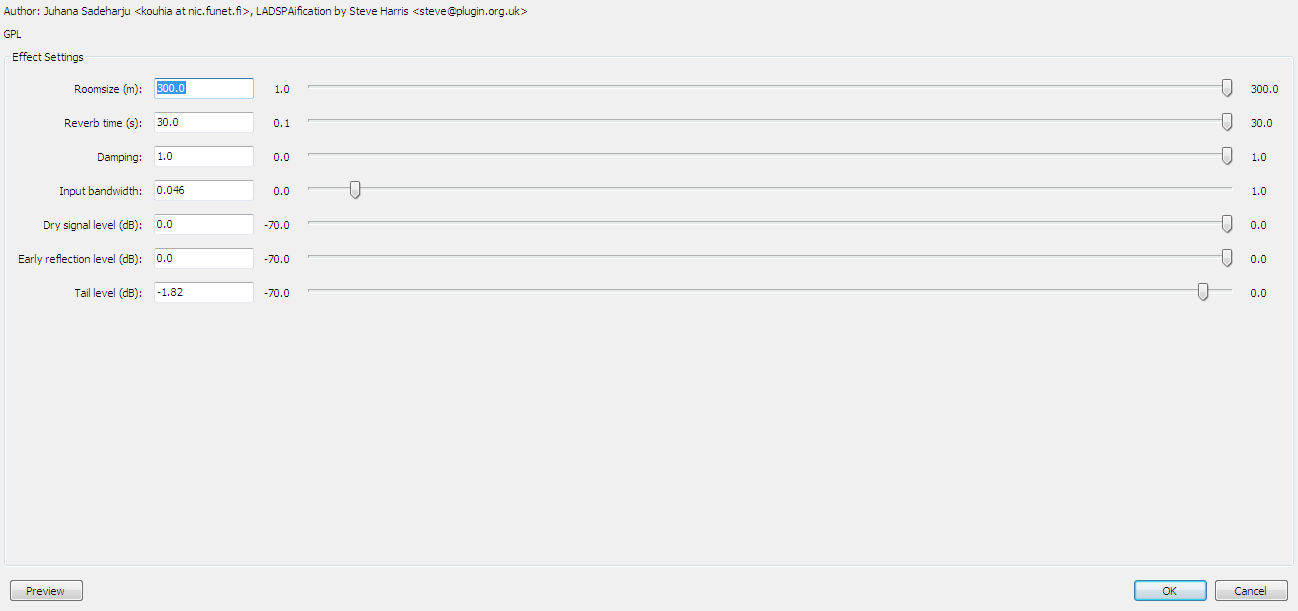
Разговоры внутри больших помещений или прочие эффекты эха можно получить при помощи ревербератора или делея, с его же помощью можно сделать механический голос:

Звук "за стенкой" легко сделать, отрезав верхние частоты:
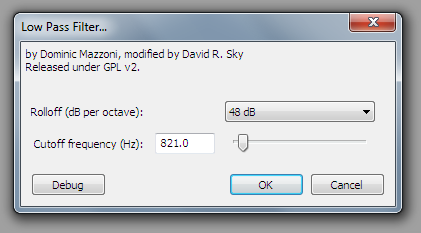
Как альтернативу, можно использовать фильтр Bass Boost
Эффект мультипликационных героев можно получить через Change Pitch, равно как и наоборот, более маскулинных персонажей:
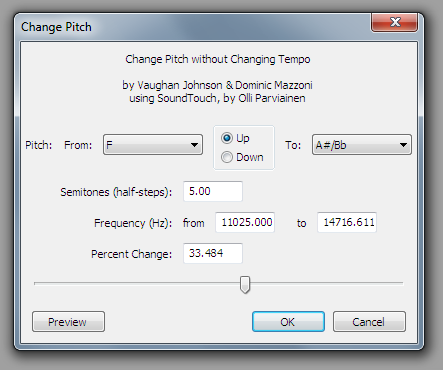
При помощи этого же эффекта можно создавать робо-голоса, создавая несколько дорожек с разными настройками и накладывая их друг на друга
Голос приведений можно сделать при помощи уже знакомого ревербератора, однако сначала надо выделить нужный участок и через Effects → Reverse обратить его воспроизведение наоборот, применить эффект реверберации, а затем вернуть воспроизведение обратно, еще раз вызвав Effects → Reverse. Обратите внимание, что эффект реверберации увеличивает время звучания, поэтому заранее отдайте ему немного больше времени, а хвост можно приглушить при помощи Fade Out.
Если вам нужны какие-то другие эффекты или вы знаете способ создания интересных эффектов голоса — пишите.
Практически все эти эффекты можно получить в любом редакторе, скриншоты Audacity приведены просто для примера.
Нарезка файла
Итак, у нас есть готовый файл. Он почищен и в нем проставлены эффекты. Можно отсылать? Еще минуточку! Нарежьте его на фразы!

Не надо падать в обморок, выделяя каждую реплику и сохраняя в каждый файл отдельно. Все гораздо проще и удобнее!
Вы видите, что иногда паузы присутствуют в самих диалогах? А еще какой-то мелкий мусор между ними? Давайте его уберем. Я поступаю так:
- Выделяю кусочек тишины, секунд 5. Если тишины мало, то ее можно скопировать несколько раз, пока не будет достаточно.
- Нажимаю CTRL+L или кнопку Silence

- Копирую получившийся шаблон тишины
- Выделяю участки между фразами (не перепутайте!), за одно в выделение попадает мусор
- Нажимаю CTRL+V, тем самым замещая оригинальный звук на тишину
Получается примерно вот так:

Если же при самой записи делать паузы, то этого можно или избежать, или значительно упростить операцию. Для этого при начитке, между диалогонами, про себя повторяйте "миссис-сиппи-раз, миссис-сиппи-два, миссис-сиппи-три", что как раз даст примерно 3 секунды паузы. А еще лучше прочитать сам диалог 2-3 раза про себя, а уже потом его озвучить, записанная тишина будет отличным разделителем.
Если ваш редактор не поддерживает нарезания файлов, то просто сохраните все получившееся (вместе с паузами) во FLAC/WAV (48000hz, 16 bit) и переходите в пукнт 5.
А в случае Audacity идем в Analize → Sound Finder и делаем примерно такие настройки:
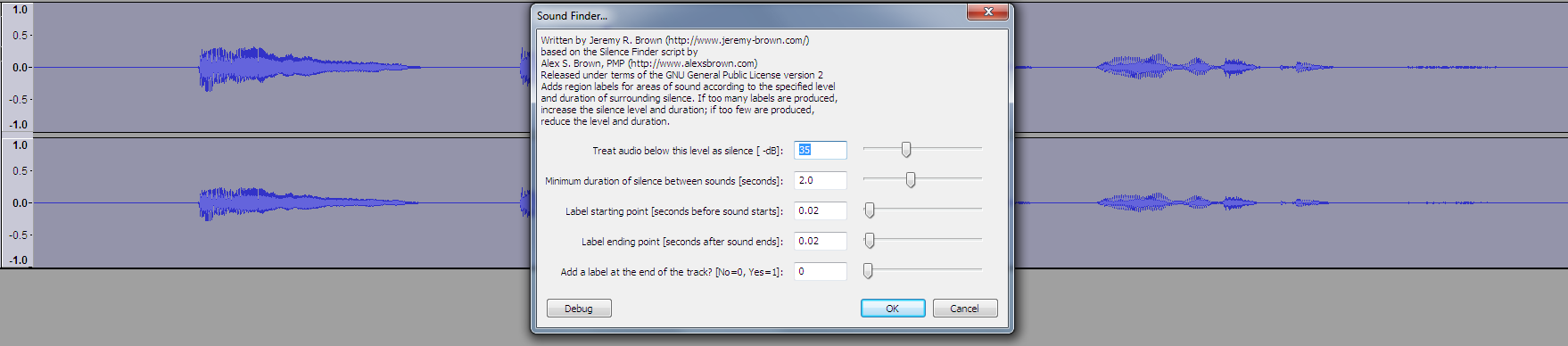
Обратите внимание, что мы по 0.02 секунды берем с каждой стороны, это важно. Жмем ОК и получаем трек с метками. Именно по границам этих меток у нас и будет разрезание:
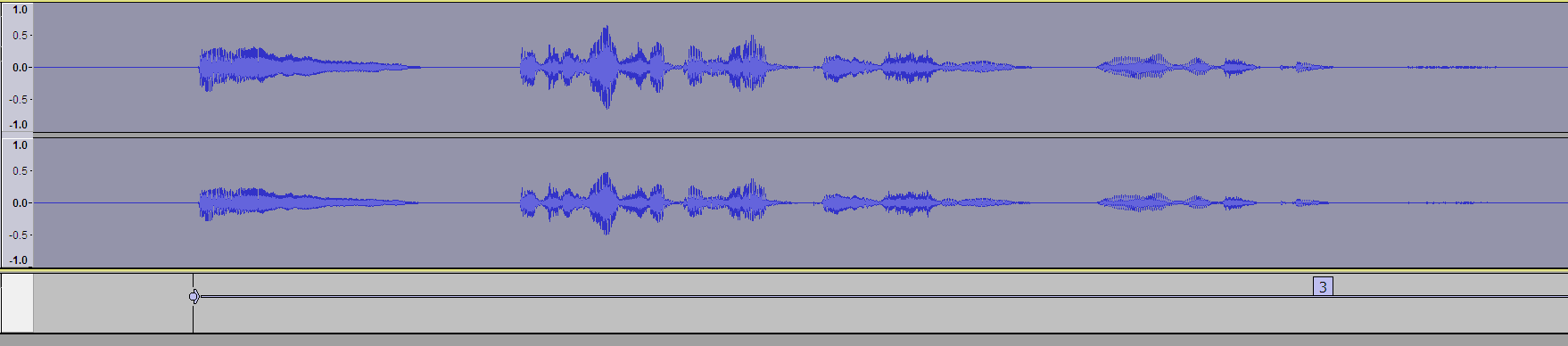
Теперь наши фразы можно экспортировать в отдельные фразы, для этого зайдем в File → Export Multiple:
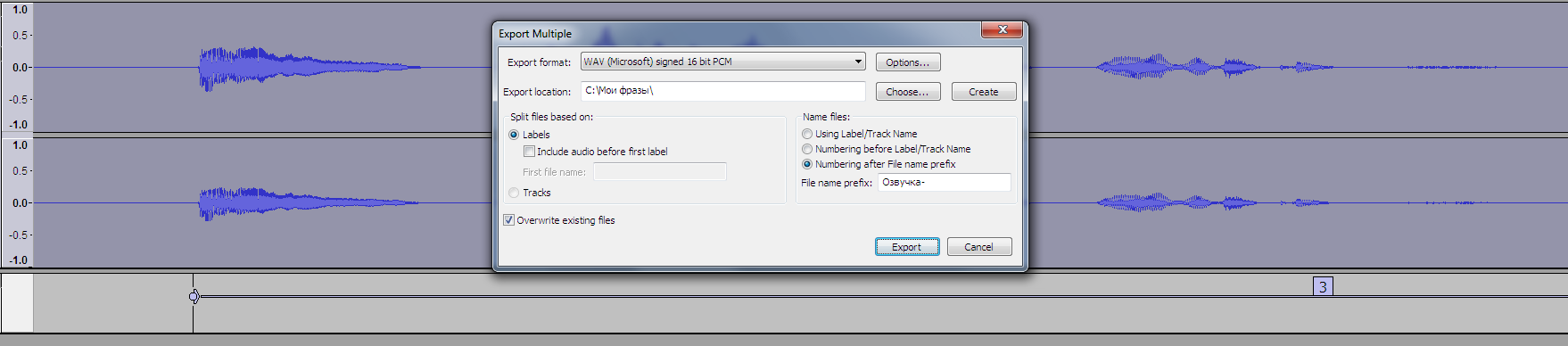
Тут все очень просто: указываем куда сохранять наши файлы, префикс для имен и тип файлов, который должен быть "FLAC" или "WAV signed 16 bit PCM".
Затем много-много раз нажимаем ok, если включено указание метаданных. Если вы записали порядка 500 фраз, а нажимать на кнопку "ок" 500 раз не хотите, то можно зайти в настройки Edit → Preferences → Import/Export и выключить галку напротив "Show Metadata Editor".
Сохранение и отправка
В итоге у тебя должен быть один длинный файл с участками тишины (не менее 3х секунд!), или множество мелких файлов. ВНИМАНИЕ! Количество фраз в твоем задании должно совпадать с количеством записанных фраз! Без единого пропуска! Если что-то не можешь озвучить — уточни заранее, но не делай пропусков!
Еще раз напомню спецификации файлов:
- Кодек/формат: FLAC 16 bit, WAV PCM 16 bit, WAV PCM 24 bit, WAV PCM 32 bit (лучше без флоат)
- Каналы: так как рот у тебя один, то лучше сделать Mono, но если пришлешь в Stereo, то никто не будет обижен
- Samplerate или частота дискретизации: 44100 или 48000 герц. Выбирай тот, который у тебя установлен в настройках и на твоей звуковой карте.
Никаких mp3, ogg, wma и тому подобного! Мне не сложно перевести из формата в формат, это займет доли секунды, но упущенного качества будет не вернуть!
Все что у тебя получилось сжимай через Winrar, не забыв указать пароль и шифрование имен файлов.
Если озвучка была за несколько персонажей, то их диалоги лучше сохранять с разными префиксами, а не перемешивать.
Впрочем, это предпочтение, если тебе удобнее писать сразу всех своих персонажей, то делай как удобнее, просто укажи, что диалоги смешаны.
Ну и маленькая смешняфка: